
This is a two-part series about how Guidewire simplifies outbound integrations with Application Events and Integration Gateway in InsuranceSuite Cloud.
In Part One, we covered integrations: what makes them complex in Property and Casualty (P&C), and what we’re doing to make them simpler in Guidewire Cloud Platform (GWCP). Now, in Part Two we’ll show you how Guidewire’s Application Events works with an under-the-hood view.
Watch the Video Presentation
If you’d like to see both parts in full presented by Guidewire’s Director of Product Management, Simon Reading, and Senior Software Architect, Mark Bolger, watch the video below. The under-the-hood walkthrough of “How App Events Works” begins at 27:28.
How Guidewire’s Application Events Works
With that, let’s talk about how App Events actually works, because you may be more familiar with Guidewire’s event messaging, which App Events will replace. It’s good to see exactly what we are providing above and beyond what event messaging does today.
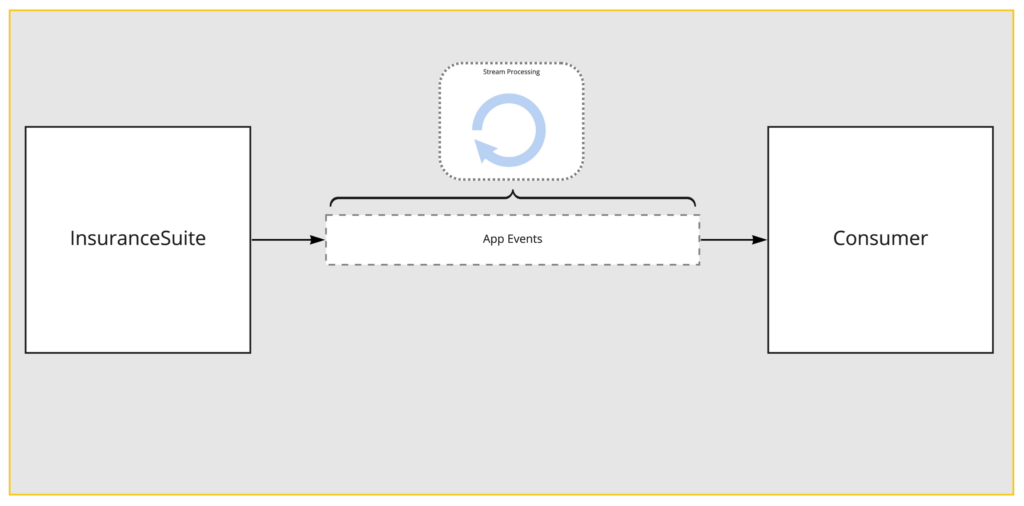
At a high level, App Events is a stream-processing pipeline between InsuranceSuite and the consumer. As you saw, consumers always receive an entire snapshot of the data. You can also guess that InsuranceSuite cannot create this entire snapshot at every transaction in the system. That is what the App Events system is for.
To start our example at the beginning, there is a new messaging destination inside of ClaimCenter or PolicyCenter. And the job of this destination is to collect all the existing events via event-fired rules and produce data for them for our other system. It listens to all ORM events, and every ORM event is attached to an entity. It takes that entity, maybe a claim exposure incident, and looks up the view of that entity in the Cloud APIs. So whatever integration view is attached to that entity, it will make use of.
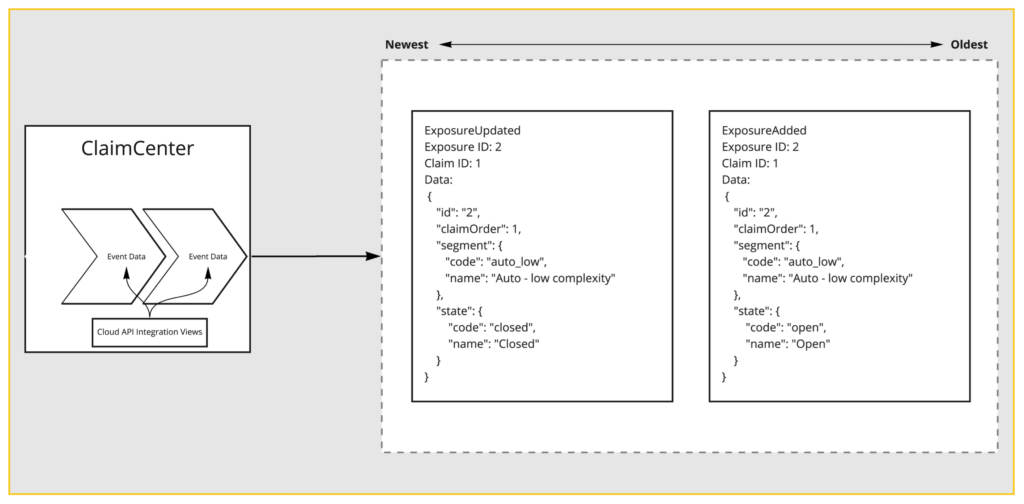
If you’re not familiar with integration views, they are a successor to GX models. They are the combination of a schema and a mapping, which produces a model — in our case of JSON — often an entity and various mappings.
You can see here an exposure was added, and we have exposure data along with it. Then, an exposure was updated, and we have exposure data along with it. In our case, it went from Open to Closed, but the key here is that it’s only exposure data. If the exposure’s changed, we receive exposure data. Of course, this is not what the downstream consumers show.
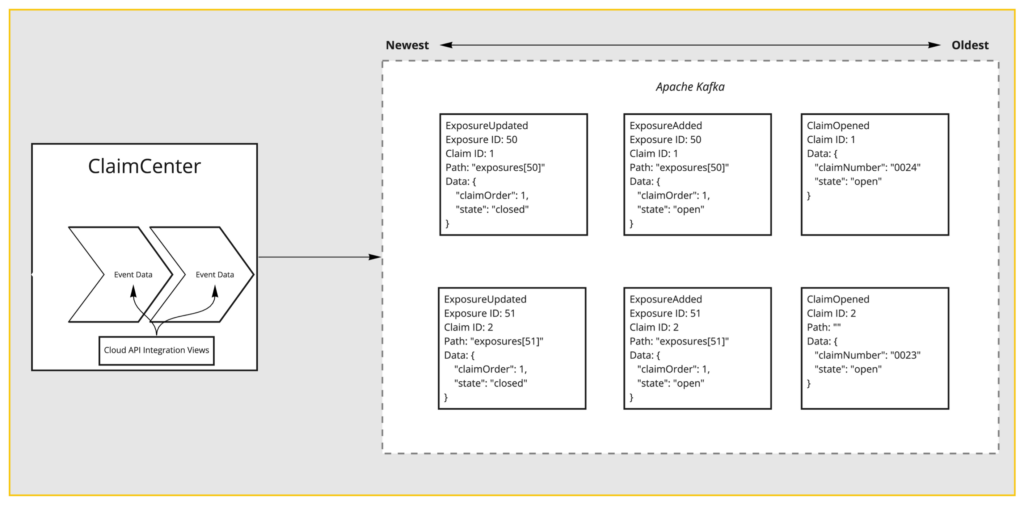
Before we dive into how we ended up with the full payload, let’s point out technology again. Apache Kafka is what we’re using. Our partitioning scheme maintains safe ordering guaranteed by event messaging. We use claim ID or account ID and policy for our partition keys. This ensures that while we operate at scale and process many claims at the same time, we will process a particular claim’s set of events strictly in order. And you will receive them strictly in order as well.
From here, we reach a system that we call the App Event Processor. And the App Event processor’s job is fairly simple on the surface. It receives these data updates from InsuranceSuite. It uses a state storage engine to store snapshots of that claim. It does that by looking up the previous snapshot, applying the update, and then storing the new snapshot. It then propagates the events downstream where consumers can receive them and then look up the snapshot for their own use. Again, it’s doing this constantly, parallelized across many claims.
We maintain partition keys — again, maintaining that safe ordering from InsuranceSuite all the way to the consumer. The storage engine we’ve built on top of a combination of Dynamo and S3. We’ve done this because Dynamo has size limits and S3 does not, at least not similar sizes. So we can handle large documents, but we have the advantage of latency that we get from Dynamo. This thing can work very fast.
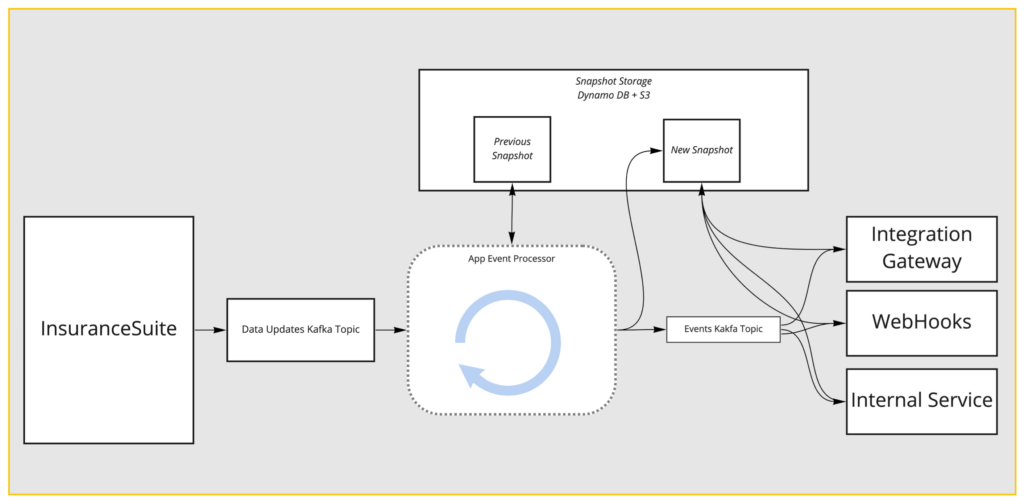
Consumers like Integration Gateway, Webhooks, or even our Internal Services — which want to kick off these same events as well — hit our snapshot storage (Dynamo DB) in order to drive other processes without putting load on InsuranceSuite.
So back to the first picture we had, ClaimCenter has produced two changes: an “ExposureAdded” and an “ExposureUpdated” event. We can see that the “ExposureAdded” was the exposure 50. It was against Claim 1. And in this case, the data was of state “Open.” And in the “ExposureUpdated” example, it’s on the same claim, same exposure, but it is now “Closed.” The processor takes the added event, it reads the last.
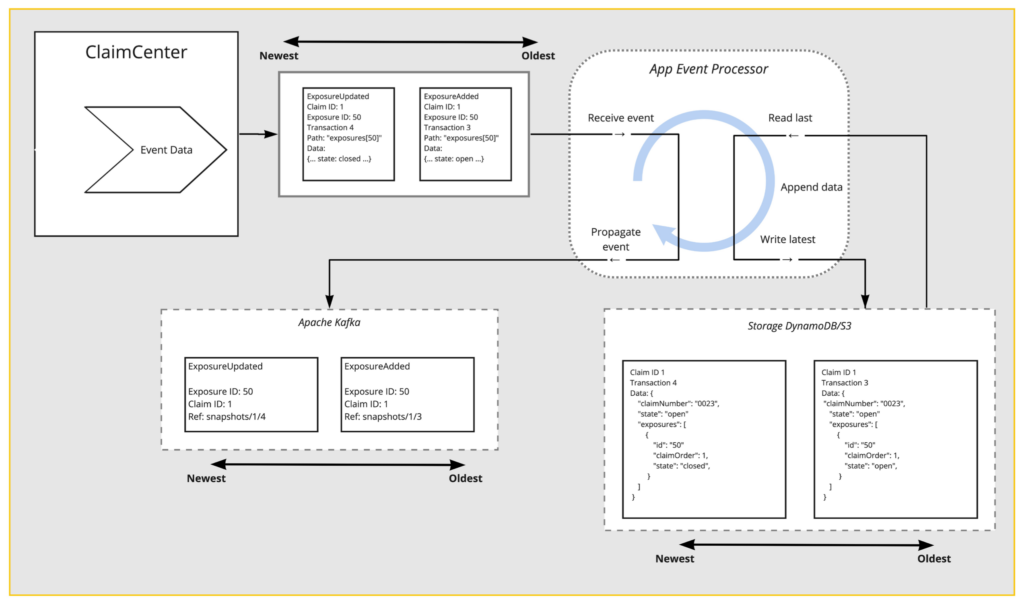
In this case, we are looking up the last version of Claim 1 and we apply that update. Notice that there is a header I haven’t explained yet, it’s called “Path.” This tells us where the changed data belongs in the entire schema. In claim the updated data is at the path exposures, or the ID is 50.
Of course, an added event is going to be new. Our processor inserts this exposure at that spot. It then writes the new version of Claim 1 and propagates the “ExposureAdded” event downstream.
The “ExposureUpdated” event comes in. We see the exact same process occurring. It looks up Claim 1, applies the update to exposure 50 in place. It then propagates the “ExposureUpdated” event downstream. Now, in a real running system, there’s not just one event per transaction. There are many and can be a fairly large number of events. Semantically, when one transaction has many events, they all happen simultaneously. Our processor and our snapshot storage do not store intermediate state.
The granularity of every claim is true to the time the event occurred, even though many events occur at the exact same time, which you can see in the downstream system. The references are to the snapshots database, the particular claim, and the transaction ID for the claim that we care about. We mentioned how downstream systems may be in the form of financials. It’s very important that these are early bound.
If something is added and removed in quick succession, it will be captured during the first transaction state of that claim and then it will be gone in the second. But integrations have an opportunity to react to both of those things in time. They do not lose the visibility of something added and removed. And that’s it. This downstream topic is what webhooks plug into. It’s what Integration Gateway plugs into. Both use Apache Kafka directly in order to maintain that safe ordering still. Both of those systems go to our snapshot storage engine for you before sending the data to your route or to your system via HTTP.
Application Events and Integration Gateway
Currently, Application Events and Integration Gateway are part of our Early Access (EA) Program for the Guidewire Cloud Platform.
If you’re interested in using one of the integration frameworks for one of your integrations, then you should talk to your Customer Success Manager about leveraging the frameworks and being part of our Early Access program.
If you’re one of our partners who’s interested in using one of the new frameworks, you should talk to your Alliances Manager and express interest so we can start getting you set up.
About the Authors

Simon Reading
Director of Product Management

Mark Bolger
Senior Software Architect